XDP:手把手教你写SD-WAN“路由器”
摘要
最近发现了一个好玩的东西- XDP,这是一个位于操作系统协议栈之前的“钩子”,也就意味着可以在这里做一些小动作,比如在这里丢弃的包,用tcpdump是看不到的。本文主要介绍了通过使用XDP(ebpf)来描述一个SD-WAN场景的转发设备来实现透明网络接入,或者称其为:路由器or 交换机,如果你愿意的话。这里重点介绍了通过XDP实现的两个功能:TUNNEL封装、转发。
XDP简介
在讨论xdp之前我想先简单介绍一下(e)bpf,bpf是一个通用的RISC指令集,最初设计用于在C的子集中编写程序,可以通过编译器后端(例如LLVM)将其编译为BPF指令,然后通过内核中的JIT编译器将其映射到本机操作码中,以在内核中实现最佳执行性能。
xdp代表eXpress数据路径,为BPF提供框架,支持Linux内核中的高性能可编程数据包处理。它在软件中尽可能早地运行BPF程序,即在网络驱动程序接收数据包时。xdp 使用ebpf 做包过滤,相对于dpdk将数据包直接送到用户态,用用户态当做快速数据处理平面,xdp是在驱动层创建了一个数据快速平面。在数据被网卡硬件dma到内存,分配skb之前,对数据包进行处理。由于完全不存在锁操作。且bypass了协议栈,非常适合用修改数据包并转发,数据探针,执行丢包。

在XDP子系统中,我们可以在程序中使用一些map映射(K-V),通过bpftool可以加载或者查看这些映射条目,可以实现网络设备中常见的的match -> action模型, 当然这个match我们可以通过简单的C语言定义,比如选择ip或者tcp包头中的某个或者某些字段,action可以是redirect的一个出口NIC或者是一个tunnel的封装。这让我想到了P4,实在是太疯狂了,这让我立刻决定写下这边文章,把一些想法记录下来。

XDP与Linux内核及其基础架构协同工作,这意味着内核不会像在用户空间中运行的各种网络框架那样被绕过。将数据包保留在内核空间中有几个主要优点:
- XDP能够在BPF帮助程序调用本身中重用所有上游开发的内核网络驱动程序,用户空间工具,甚至其他可用的内核基础结构,如路由表,套接字等。
- 驻留在内核空间中的XDP与内核的其余部分具有相同的安全模型,用于访问硬件。
- 不需要跨越内核/用户空间边界,因为已处理的数据包已经驻留在内核中,因此可以灵活地将数据包转发到其他内核实体,例如容器或内核的网络堆栈本身使用的命名空间。这在Meltdown和Spectre时期特别相关。
- 将数据包从XDP分配到内核强大,广泛使用且高效的TCP / IP堆栈是非常可能的,允许完全重用,并且不需要像用户空间框架那样维护单独的TCP / IP堆栈。
- BPF的使用允许完全可编程性,保持稳定的ABI与内核的系统调用ABI具有相同的“永不中断用户空间”保证,并且与模块相比,它还提供安全措施,这要归功于BPF验证器确保内核操作的稳定性。
- XDP通常允许在运行时自动交换程序,而不会出现任何网络流量中断甚至内核/系统重启。
- XDP允许灵活地构建集成到内核中的工作负载。例如,它可以在“忙碌轮询”或“中断驱动”模式下操作。不需要将CPU显式专用于XDP。没有特殊的硬件要求,也不依赖于大页面。
- XDP不需要任何第三方内核模块或许可。它是一个长期的架构解决方案,是Linux内核的核心部分,由内核社区开发。
- XDP已经启用并随处运送,主要发行版运行相当于4.8或更高的内核,并支持大多数主要的10G或更高版本的网络驱动程序。
场景描述
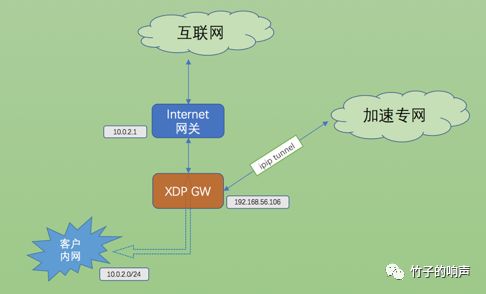
场景一:SD-WAN的透明接入
在SD-WAN或者一些其他的场景,常常要求透明接入一些设备,以防变动用户当前的网络。因此,此方案是在用户网络与公网网关之间串入一个设备(暂且称其为SD-WAN网关),以实现将重要或者感兴趣的流量封装成IPinIP报文通过专用的加速网络送到目的地。
场景二:DPI(棱镜) 版本一:物理层
此版本原型来自lan2tap,但是有个限制:最大只支持到百兆
版本二:内核netfilter hook + tap
在prerouting链上挂在自定义的钩子过滤函数,将感兴趣流转发到tap接口,再通过tap接口将流量从用户空间导出。
版本三:XDP Redirect
直接通过bpf_redirect或bpf_redirect_map函数,将感兴趣流转发至目标端口,此版本在性能上可以媲美DPDK,可玩性也比较高。
SEC("xdp_redirect")
int xdp_redirect_prog(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
int rc = XDP_DROP;
int *ifindex, port = 0;
long *value;
u32 key = 0;
u64 nh_off;
nh_off = sizeof(*eth);
if (data + nh_off > data_end)
return rc;
ifindex = bpf_map_lookup_elem(&tx_port, &port);
if (!ifindex)
return rc;
value = bpf_map_lookup_elem(&rxcnt, &key);
if (value)
*value += 1;
swap_src_dst_mac(data);
return bpf_redirect(*ifindex, 0);
}
/* Redirect require an XDP bpf_prog loaded on the TX device */
SEC("xdp_redirect_dummy")
int xdp_redirect_dummy_prog(struct xdp_md *ctx)
{
return XDP_PASS;
}实现方案
TUNNEL封装 流量模型 出向流量(由本地内网发出)
SD_WAN 网关在用户侧端口收到的数据包:

SD_WAN 网关在用户侧端口入方向封装通过加速专线端口转发:

入向流量(到达本地内网)
SD_WAN 网关在加速专线网络侧端口收到的数据包:

SD_WAN 网关在在加速网络侧端口入方向解封装通过用户侧端口转发:

CODE
部分代码实现如下,另外也可以参考github上面的bpf-samples项目
/* allocate a destination using packet hash and map lookup */
tnl = hash_get_dest(&pkt);
if (!tnl)
return XDP_DROP;
/* extend the packet for ip header encapsulation */
if (bpf_xdp_adjust_head(ctx, 0 - (int)sizeof(struct iphdr)))
return XDP_DROP;
data = (void *)(long)ctx->data;
data_end = (void *)(long)ctx->data_end;
/* relocate ethernet header to start of packet and set MACs */
new_eth = data;
old_eth = data + sizeof(*iph);
if (new_eth + 1 > data_end || old_eth + 1 > data_end ||
iph + 1 > data_end)
return XDP_DROP;
set_ethhdr(new_eth, old_eth, tnl, bpf_htons(ETH_P_IP));
/* create an additional ip header for encapsulation */
iph_tnl.version = 4;
iph_tnl.ihl = sizeof(*iph) >> 2;
iph_tnl.frag_off = 0;
iph_tnl.protocol = IPPROTO_IPIP;
iph_tnl.check = 0;
iph_tnl.id = 0;
iph_tnl.tos = 0;
iph_tnl.tot_len = bpf_htons(payload_len + sizeof(*iph));
iph_tnl.daddr = tnl->daddr;
iph_tnl.saddr = tnl->saddr;
iph_tnl.ttl = 8;
/* calculate ip header checksum */
next_iph_u16 = (__u16 *)&iph_tnl;
#pragma clang loop unroll(full)
for (int i = 0; i < (int)sizeof(*iph) >> 1; i++)
csum += *next_iph_u16++;
iph_tnl.check = ~((csum & 0xffff) + (csum >> 16));
iph = data + sizeof(*new_eth);
*iph = iph_tnl;
/* increment map counters */
pkt_size = (__u16)(data_end - data); /* payload size excl L2 crc */
__sync_fetch_and_add(&tnl->pkts, 1);
__sync_fetch_and_add(&tnl->bytes, pkt_size);
return bpf_redirect_map(&tx_port, ifaceid, 0);
}XDP确保程序可以使用256字节的额外空间,在BPF帮助程序-bpf_xdp_adjust_head()的帮助下实现自定义封装头,或者在数据包前添加自定义元数据bpf_xdp_adjust_meta()。
XDP中通过上下文传递给BPF程序的数据包表示如下所示:
struct xdp_buff {
void * data ;
void * data_end ;
void * data_meta ;
void * data_hard_start ;
struct xdp_rxq_info * rxq ;
};data指向页面中分组数据的开始,顾名思义,data_end指向分组数据的末尾。由于XDP允许256字节的额外空间,data_hard_start指向页面中可能的最大空间开始,这意味着,当数据包应该被封装时,通过bpf_xdp_adjust_head()辅助函数,data移动到更靠近data_hard_start的地方。相同的BPF辅助函数也允许解封装,在这种情况下data会进一步远离data_hard_start。 data_meta最初指向相同的位置,bpf_xdp_adjust_meta()也能够将指针移向data_hard_start ,以便为普通内核网络堆栈不可见的自定义元数据提供空间,但可以由tc BPF程序读取,因为它从XDP传输到skb。反之亦然,它可以通过相同的BPF辅助函数删除或减少自定义元数据的大小,方法是再次data_meta离开data_hard_start。data_meta也可以单独用于在尾调用之间传递状态,类似于skb->cb[]在tc BPF程序中可访问的控制块情况。
场景测试
通过在加速专网侧的端口抓包,我们可以看到封装后的数据报文

路由转发
像传统的网络设备,比如路由器或者交换机是区分二层转发、三层转发的,那传统的网络设备收到一个报文是如何判断应该而是二层转发(交换)还是三层转发(路由)呢?一名来自ZTE的老网工告诉我,是根据报文的二层目的MAC,如果MAC地址是网络设备自身的MAC,就执行路由查询转发动作,如果不是则执行二层转发(交换)。
但是随着云计算SDN的发展,OVS的崛起,渐渐的二三层转发的概念逐渐被模糊或者遗忘了,剩下的只有match -> action ,以及各种overlay、tunnel的封装。
在这里我们简单介绍一个内核中的一个例子,在linux/samples/bpf/xdp_router_ipv4_kern.c 中简单实现了路由转发功能,转发面是直接调用了bpf_redirect_map(&tx_port, forward_to, 0) 辅助函数,控制面是通过用户态的程序(c或者pyhton)直接读取了linux中的路由表以及arp表,然后生成bpf中定义的map,由xdp_router_ipv4_kern.c 调用该map,获取转发相关的信息(下一跳出口、封装所需的二层MAC信息)实现报文的转发。
#路由查询相关map
key:32位的前缀长度+ 32位路由前缀
value: 32位的前缀+ 路由出接口MAC地址+ 32位路由出接口id + 32位开销值+ 32位下一跳IP地址
/* Map for trie implementation*/
struct bpf_map_def SEC("maps") lpm_map = {
.type = BPF_MAP_TYPE_LPM_TRIE,
.key_size = 8,
.value_size = sizeof(struct trie_value),
.max_entries = 50,
.map_flags = BPF_F_NO_PREALLOC,
};
#内核路由表:
root@ubuntu18:~# ip ro
4.4.4.0/31 via 192.168.56.1 dev enp0s8
4.4.4.4 via 192.168.56.1 dev enp0s8
192.168.56.0/24 dev enp0s8 proto kernel scope link src 192.168.56.106
#对应生成的map表:
root@ubuntu18:~# bpftool map dump id 97
key:
1f 00 00 00 04 04 04 00
value:
04 04 04 00 00 00 00 00 08 00 27 90 56 e3 00 00
03 00 00 00 00 00 00 00 c0 a8 38 01 00 00 00 00
key:
20 00 00 00 04 04 04 04
value:
04 04 04 04 00 00 00 00 08 00 27 90 56 e3 00 00
03 00 00 00 00 00 00 00 c0 a8 38 01 00 00 00 00
key:
20 00 00 00 09 09 09 10
value:
09 09 09 10 00 00 00 00 08 00 27 90 56 e3 00 00
03 00 00 00 00 00 00 00 c0 a8 38 01 00 00 00 00
key:
20 00 00 00 09 09 09 20
value:
09 09 09 20 00 00 00 00 80 00 27 90 56 e3 00 00
03 00 00 00 00 00 00 00 c0 a8 38 01 00 00 00 00
key:
18 00 00 00 c0 a8 38 00
value:
c0 a8 38 00 00 00 00 00 08 00 27 90 56 e3 00 00
03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Found 5 elements
root@ubuntu18:~##设备接口相关map
kay跟value均是32位的ID,辅助函数bpf_redirect_map通过该map可以直接告诉告诉内核要转发出去的端口
struct bpf_map_def SEC("maps") tx_port = {
.type = BPF_MAP_TYPE_DEVMAP,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 100,
};
root@ubuntu18:~# bpftool map dump id 101
can't lookup element with key:
00 00 00 00
can't lookup element with key:
01 00 00 00
key: 02 00 00 00 value: 02 00 00 00
key: 03 00 00 00 value: 03 00 00 00#ARP相关map
key:32位的下一跳IP地址
value: 48位的MAC地址
/* Map for ARP table*/
struct bpf_map_def SEC("maps") arp_table = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(__be32),
.value_size = sizeof(__be64),
.max_entries = 50,
};
root@ubuntu18:~# bpftool map dump id 99
key: c0 a8 38 64 value: 08 00 27 eb 1d 51 00 00
key: c0 a8 38 01 value: 0a 00 27 00 00 00 00 00
key: 00 00 00 00 value: 00 00 00 00 00 00 00 00
Found 3 elements
root@ubuntu18:~# arp -a
? (192.168.56.100) at 08:00:27:eb:1d:51 [ether] on enp0s8
? (192.168.56.1) at 0a:00:27:00:00:00 [ether] on enp0s8
root@ubuntu18:~#通过以上信息已经可以确认从哪个端口转发出去,以及转发出去时对二层包头填充所需的信息,通过这种方式实现的转发,个人觉得比纯用户态的实现要简单一些,并不是说像DPDK这种纯bypass的方案不好,DPDK之所以能够红透半边天,肯定有很多优点在里面的,但是今天我们在这里讨论的是XDP,当时希望XDP能够发展起来的。
展望未来
我们都知道Cilium是基于eBPF和XDP实现的相对容器透明的网络方案,也是Google主推的一个方案,这种相对底层的实现,可以达到接近最佳的性能。这也允许我们定制具有商用硬件级别高性能负载平衡器或路由器。XDP带来的一个优势还在于它重用内核的安全模型来访问设备而不是基于用户空间的机制。它不需要任何第三方模块,并与Linux内核协同工作,希望XDP能够顺利的走下去。