Elasticsearch常用命令
启动和关闭
前台方式
# 启动
./bin/elasticsearch
# 关闭(同时按下Ctrl键和C键)
Ctrl+C后台方式(进程id记录在elasticsearch.pid文件)
# 启动
./bin/elasticsearch -d -p elasticsearch.pid
# 关闭
pkill -F elasticsearch.pid创建索引
创建索引test2(有name、age、birthday三个属性,类型分别为text、long、date)
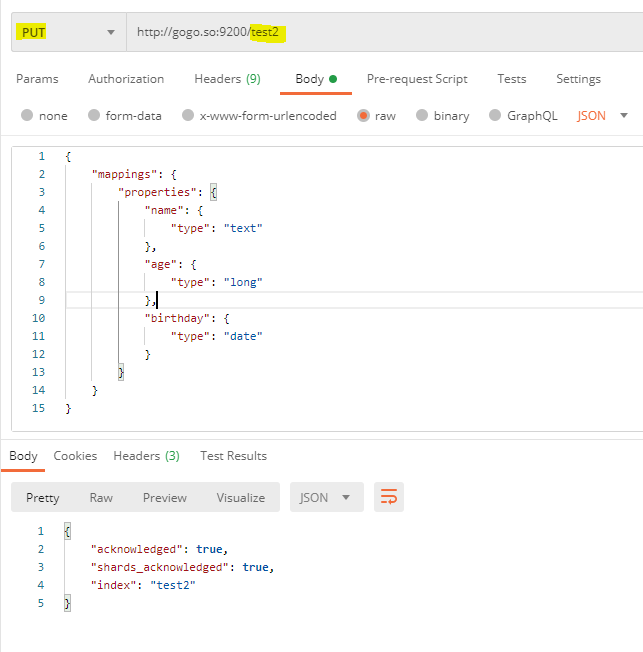
参考
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}获取索引信息
获取索引test2的具体信息
curl 'localhost:9200/test2?format=json&pretty'
获取索引的文档数
获取file_meta索引文档总数
curl -X GET "localhost:9200/file_meta/_count"获取file_meta索引中date_tag为20210414的文档总数
curl -X GET "localhost:9200/file_meta/_count?q=date_tag:20210414&pretty"删除索引
删除索引test2,使用(DELETE请求)
curl -X DELETE http://gogo.so:9200/test2查询
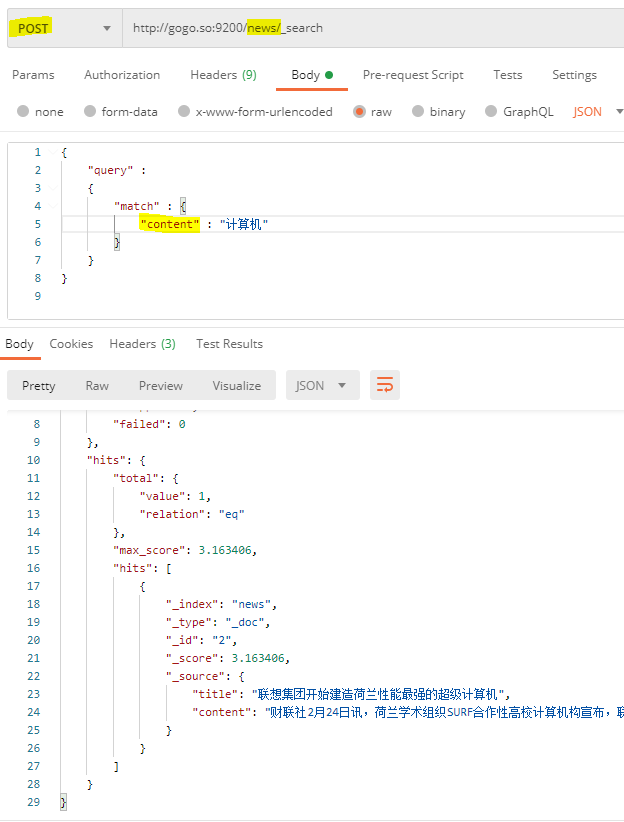
在索引news中查询content字段中包含关键字【计算机】的文档
列出所有索引
# 默认方式
curl 'localhost:9200/_cat/indices'
# 输出更详细的(verbose)的信息
curl 'localhost:9200/_cat/indices?v'
# 以json格式输出结果,并格式化
curl 'localhost:9200/_cat/indices?format=json&pretty'列出索引中的所有文档
列出file_meta索引中的所有文档(必须指定size参数,不指定为话,size的默认值为10,默认最多返回10条)
curl -X GET "localhost:9200/file_meta/_search?size=100&pretty" -H 'Content-Type: application/json' -d'
{
"from": 40, // 相当于Mysql的offset参数,默认值 为0
"size": 20, // 相当于Mysql的limit参数
"query": {
"match_all": {}
}
}
'测试分词
测试分词(下面的ik_smart也可以换为ik_max_word)
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
'根据文档id获取文档数据
从索引file_meta中获取文档id为 0RGRbbOzROCmPbrEYTUhQpKgNFFxiVCz的数据
curl 'localhost:9200/file_meta/_doc/0RGRbbOzROCmPbrEYTUhQpKgNFFxiVCz'搜索文档
根据关键词从文档file_meta中搜索数据(下例中的字段为【description】,关键词为【蚂蚁】)
curl -X GET "localhost:9200/file_meta/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"description": "蚂蚁"
}
}
}
'根据文档id删除文档数据
从文档file_meta_test中删除id为 0RGRbbOzROCmPbrEYTUhQpKgNFFxiVCz的数据
curl -X DELETE "localhost:9200/file_meta_test/_doc/0RGRbbOzROCmPbrEYTUhQpKgNFFxiVCz?pretty"创建索引
# 创建file_meta索引
curl -X PUT "localhost:9200/file_meta" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"file_id": {
"type": "text",
"index": false
},
"filename": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"date_tag": {
"type": "integer"
},
"filetype": {
"type": "integer"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
'
# 创建po索引
curl -X PUT "localhost:9200/po" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"po_id": {
"type": "text",
"index": false
},
"date_tag": {
"type": "integer"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
'参考
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/rest-apis.html
其它链接
Elasticsearch搜索引擎第三篇-ES集成IKAnalyzer中文分词器
Elasticsearch中analyzer和search_analyzer的区别
不参与查询的字段
The index option controls whether field values are indexed. It accepts true or false and defaults to true. Fields that are not indexed are not queryable.
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/mapping-index.html
最佳实践
string类型已经被废弃,被拆分为keyword和text两种。
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。