Linux网络笔记
Linux内核源码 https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/
在 TCP/IP ⽹络分层模型⾥,整个协议栈被分成了物理层、链路层、⽹络层,传输层和应⽤层。物理层对应的是⽹卡和⽹线,应⽤层对应的是我们常⻅的 Nginx,FTP 等等各种应⽤。Linux 实现的是链路层、⽹络层和传输层这三层。在 Linux 内核实现中,链路层协议靠⽹卡驱动来实现,内核协议栈来实现⽹络层和传输层。内核对更上层的应⽤层提供 socket 接⼝来供⽤户进程访问。
2.4 以后的内核版本采⽤的下半部实现⽅式是软中断,由 ksoftirqd 内核线程 全权处理。和硬中断不同的是,硬中断是通过给 CPU 物理引脚施加电压变化,⽽软中断是通 过给内存中的⼀个变量的⼆进制值以通知软中断处理程序。

内核收包的流程
当⽹卡上收到数据以后,Linux 中第⼀个⼯作的模块是⽹络驱动。 ⽹络驱动会以 DMA 的⽅式 把⽹卡上收到的帧写到内存⾥。再向 CPU 发起⼀个中断,以通知 CPU 有数据到达。第⼆, 当 CPU 收到中断请求后,会去调⽤⽹络驱动注册的中断处理函数。 ⽹卡的中断处理函数并不 做过多⼯作,发出软中断请求,然后尽快释放 CPU。ksoftirqd 检测到有软中断请求到达,调 ⽤ poll 开始轮询收包,收到后交由各级协议栈处理。对于 udp 包来说,会被放到⽤户socket 的接收队列中。
软中断中会通过 ptype_base 找到 ip_rcv 函数地 址,进⽽将 ip 包正确地送到 ip_rcv() 中执⾏。在 ip_rcv 中将会通过 inet_protos 找到 tcp 或者 udp 的处理函数,再⽽把包转发给 udp_rcv() 或 tcp_v4_rcv() 函数。
ip_rcv 中会处理 netfilter 和 iptable 过滤,如果你有很多或者很复杂的 netfilter 或 iptables 规则,这些规则都是在软中断的上下⽂中执⾏的,会加⼤⽹络延迟。

SOCKET接收数据的过程
在 Linux 上多路复⽤⽅案有 select、poll、epoll。 它们三个中 epoll 的性能表现是最优秀 的,能⽀持的并发量也最⼤。
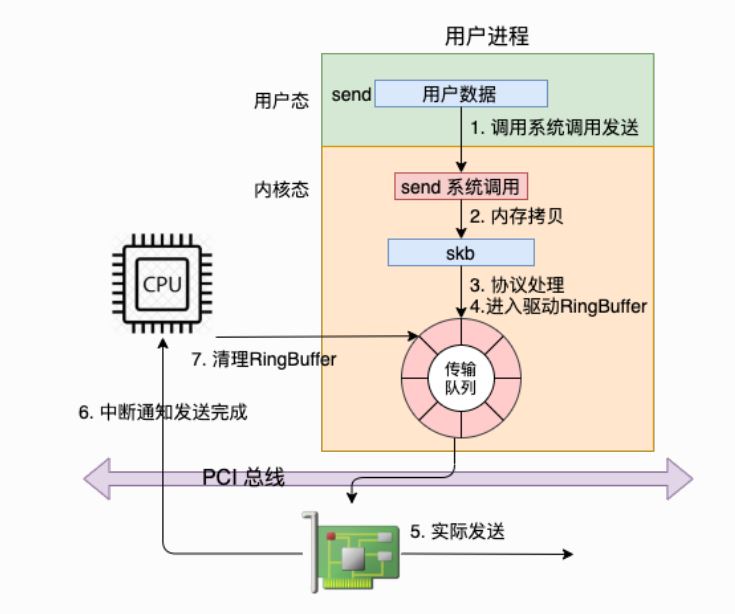
网络数据发送过程
虽然数据这时已经发送完毕,但是其实还有⼀件重要的事情没有做,那就是释放缓存队列等 内存。 那内核是如何知道什么时候才能释放内存的呢,当然是等⽹络发送完毕之后。⽹卡在发送完 毕的时候,会给 CPU 发送⼀个硬中断来通知 CPU。
现在的服务器上的⽹卡⼀般都是⽀持多队列的。每⼀个队列上都是由⼀个 RingBuffer 表示 的,开启了多队列以后的的⽹卡就会对应有多个 RingBuffer。
邻居⼦系统是位于⽹络层和数据链路层中间的⼀个系统,其作⽤是对⽹络层提供⼀个封装, 让⽹络层不必关⼼下层的地址信息,让下层来决定发送到哪个 MAC 地址。

GRO和硬中断合并的思想很类似,不过阶段不同。硬中断合并是在中断发起之前,⽽GRO已 经到了软中断上下⽂中了。 如果应⽤中是⼤⽂件的传输,⼤部分包都是⼀段数据,不⽤GRO的话,会每次都将⼀个⼩包 传送到协议栈(IP接收函数、TCP接收)函数中进⾏处理。开启GRO的话,Linux就会智能进 ⾏包的合并,之后将⼀个⼤包传给协议处理函数。这样CPU的效率也是就提⾼了。 GRO说的仅仅只是包的接收阶段的优化⽅式,对于发送来说是GSO。

Kernel bypass
使用DPDK进行Kernel bypass
获取到特定 IP 的路由
ip route get 192.0.2.3